To appear in the proceedings of the Third Conference of the European Society for Research in Mathematics Education, Bellaria, Italy, Feb. 28 - March 3, 2003.
THE QUEST OF THE BELL CURVE:
A CONSTRUCTIONIST APPROACH TO
LEARNING STATISTICS THROUGH DESIGNING
COMPUTER-BASED PROBABILITY EXPERIMENTS
Dor Abrahamson Uri Wilensky
abrador@northwestern.edu uri@northwestern.edu
Center for Connected Learning and Computer-Based Modeling
Northwestern University
![]()
![]()
![]()
This paper introduces the rationale, explains the functioning, and describes the process of developing 'Equidistant Probability', a NetLogo microworld that models stochastic behavior. In particular, we detail the phases in attempting to choose suitable parameters and create such graph displays as will permit an observer to witness the incremental growth of a bell-shaped curve. We argue that the process of building the model, and in particular the accountability, motivation, and frustration experienced, were conducive to 'connected learning' (Wilensky, 1993), through which the design of this microworld is grounded. The microworld is part of "ProbLab," a suite of Probability-and-Statistics models, which in turn is part of "Understanding Complexity," a middle-school curriculum, currently in development.
Introduction
Equidistant Probability[1] (EP) is a microworld written in NetLogo (Wilensky, 1999)--a multi-agent parallel-processing modeling environment--as part of an effort of the CCL (Center for Connected Learning and Computer-Based Modeling, http://ccl.northwestern.edu) to create software packages that support middle-school students' learning of probability and statistics. The microworld and associated activities are intended to draw on students' domain-relevant personal experience and intuitions (see also Wilensky's, e.g., 1997, Connected Probability). The design of the EP microworld was done primarily by the first author (DA) guided by the second author's work on "Connected Probability" and inspired by Papert's call for increased attention to stochastics (Papert, 1996). The design was informed by a search for an environment that could pithily convey stochastic behavior as well as the workings of tools for calculation and display that describe statistical aspects of this behavior. We wished to create in this environment a suite of models, employing a single interface, that would address issues of probability from multiple directions. The result was 'Equidistant Probability', a complex suite of three sub-models: 'Equidistant' (probabilistic), 'Epicenter' ("semi-probabilistic") and 'Circumference' (geometrical-deterministic). In the spirit of constructionism (see Papert, 1980, 1991; Harel & Papert, 1991), this paper focuses mainly on DA's own learning through building 'Equidistant' and specifically on his attempts to run the model so that it would display a specific graph, the Gaussian bell-shaped or 'normal' distribution curve.
Rationale of Equidistant Probability
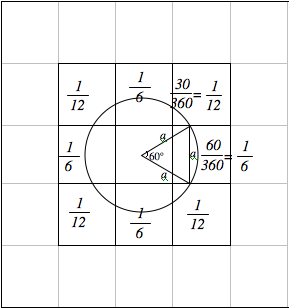
The NetLogo interface is a "patchy" world--a matrix of agent-like square locations--and so lends itself readily to conceptual metaphors drawing from space and spatiality. Inspired by discussions of this theme (Noss & Hoyles, 1996; Papert 1996; Wilensky 1996), the EP design started with the attempt to make a connection between geometry--the science of idealized space--and probability. The thinking began as follows: From a given patch in the Cartesian patch-matrix (the center of the circle in Figure 1) a 'turtle'--the Logo agent-creature--"sprouts[2]" at a random orientation and advances in discrete steps each equal in size to one patch unit. What is the chance that this walking turtle will land on each of its adjacent patches, e.g., on the patch directly to its right, as compared to the patch diagonally above it?
|
|
Figure 1: Geometric determination of the probabilities that a creature sprouting from the middle of a patch, heading in a random orientation, and stepping 1 unit forward will land on each of the 8 neighboring patches. The circle is the collection of all points 1 unit away from the source point and its radii trace steps of length 1 unit. Note the equilateral triangles (600, 600, 600). The probabilities of turtles landing in a patch are computed as the ratio between each inferred central angle subtending an arc contained within a neighboring patch and 3600, i.e. 60/360=1/6 and 30/360=1/12. ( 4 * 1/6 ) + ( 4 * 1/12 ) = 1.00
|
||||
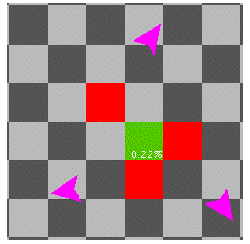
The thematic problem posed by the EP microworld becomes more geometrically familiar--relating to vertices of polygons--when one adds a second turtle that sprouts from a different patch and advances according to the same set of rules. Given that these two turtles sprout simultaneously from their respective patches, and march contemporaneously in their discrete steps, what are the chances that the turtles will land at the same time on the same patch? Note that when they do land on such a patch, then seeing as they sprouted and marched simultaneously in equally sized steps, it follows that the said patch they have now landed on (green patch, in Figure 2, below) is equally distant from their respective source (red) patches (the green patch's midpoint is the center of a new circle on the perimeter of which lie the centers of the source red patches; the distances each turtle has marched from its respective red patch into the green patch are radii in this circle).
|
Figure 2: Fragment from the interface of Equidistant Probability showing the thematic visual metaphor: From each of the (3) selected red patches (the "vertices") an arrow-shaped pink "creature" sprouts at a random orientation and darts forward. Creatures sprout simultaneously and advance in discrete steps. If all (3) creatures meet at a given patch at the same moment, then that (green) patch is equidistant from the (3) source patches. The patch label (e.g., 0.22%) indicates |
G R R R |
||||||||
|
the empirical cumulative frequency of the creatures' repeated rendezvous at that patch. This frequency will converge stochastically to the geometrically determined expected value of 0.23% (1/6 * 1/6 * 1/12). |
|||||||||
![]() Whereas two source patches
can have many equally distanced patches as rendezvous points for their turtles,
after many attempts it becomes apparent that the turtles tend to co-visit some
of these patches more than they do other patches. Also, more importantly for
this paper, three turtles, too, could find a rendezvous patch, and their
co-visiting of other patches would be rarer. For some configurations of four
(and more) source patches that do have an equidistant point there will be only a single such equidistant
rendezvous patch.
Whereas two source patches
can have many equally distanced patches as rendezvous points for their turtles,
after many attempts it becomes apparent that the turtles tend to co-visit some
of these patches more than they do other patches. Also, more importantly for
this paper, three turtles, too, could find a rendezvous patch, and their
co-visiting of other patches would be rarer. For some configurations of four
(and more) source patches that do have an equidistant point there will be only a single such equidistant
rendezvous patch.
Seeing as the turtles sprout as "blind mice," oblivious of each other as they are to the science of statistics, on the sweeping majority of attempts, when all turtles sprout and head off at random directions, they will not co-visit the same patch. But then again, sometimes they will. The questions around which EP revolves and which its prospective users ultimately address is, 'How often, if ever, will the turtles meet on the equidistant point?' and 'How, if at all, is the turtles' chance of meeting each other contingent upon their number and upon their relative positions?'
What the na�ve user does not initially know but soon discovers is that the "successful attempts"--when all the active turtles rendezvous on a single patch--are not equally dispersed across all attempts, just as a '5' does not recur at a rigid schedule across numerous rolls of a die. More analogously, perhaps, one should speak of the distributed co-occurrence of three or four 5's when rolling as many dice.
The EP environment allows one to address fundamental questions of probability, such as 'What does it actually mean, in practice (situated in Time), that an occurrence has a chance of, say, 1/1296 (1/64)?' Does the probability of an event reflect an individual observer's confidence level that it will occur as the next outcome, or does it tell us something about frequencies and limiting values (Hacking, 2001)? How are frequencies to be thought of and used--as mathematical or empirical (Biehler, 1995)? Why is it that co-occurrences are rarer than individual occurrences? How does geometrical determinism play against the slowly converging data coming from the scampering turtles? We suggest that these dichotomous epistemological and phenomenological aspects of probability--belief vs. frequency, mathematical vs. empirical, single vs. compound, and deductive vs. inductive--are addressed, pitted, and connected through the EP design.
The EP microworld is a laboratory that can scaffold and inform students' habits of research. Moving back and forth between sub-models, one can use paper-and-pencil and virtual geometry to pre-determine aspects of posed problems before one runs the model to test hypotheses, then account for disconfirming evidence that illuminates back onto one's understanding of geometry (e.g., if one had surmised an 1/8 probability of a creature landing in each of its 8 neighboring patches, one would then need to account for the variation). Perhaps, most importantly, as Papert (1996) and many others have noted, the model's computer environment affords multiple opportunities for running through and processing the outcomes of a variety of thousands of attempts within a single lesson period (compare that to the vicissitudes of rolling dice). Using the display affordances of NetLogo, one can watch how histograms that reflect the distribution of successful attempts across all attempts grow and take form, such as the proverbial bell-shaped curve. But would they indeed take that form? DA's personal learning through building EP was guided by a quest to watch a bell curve--reflecting 'normal' distribution--coalesce before his eager eyes.
DA's learning can be described as an effort to reconcile conflicts between his 'psycho-statistics' (Abrahamson & Wilensky, 2003a)--stochastic behavior patterns as interpreted by human perception, intuition, and experience--and formal mathematics (see also Gigerenzer, 1998; Biehler, 1995). In particular, these conflicts accounted for difficulty in modeling the mathematical phenomenon of the bell curve within the EP environment. The rationale and relevance of the following description is that mathematics education, and in particular modeling environments, must take such human biases into account, if we are to create tools for students to negotiate and connect mathematics to their personal experience (see Wilensky, 1997; also Abrahamson & Wilensky, 2003b, on S.A.M.P.L.E.R., Statistics As Multi-Participant Learning-Environment Resource):
The Quest
In his attempt to connect the bell-curve representation to the EP stochastics experiment, DA's initial instinct was to create code that would typify and discriminate two distinct classes of events that he was observing in the experiment outcomes: (1) 'Failure,' when the creatures did not meet; and (2) 'success' (when the creatures did meet). Next, he was faced with the task of parsing the succession of experiment outcomes so as to create data sets that would then be represented as a distribution--a distribution which, he assumed, would take the form of a bell-curve. But the question was which type of parsing would lead to the bell-curve distribution?
Let us assume that the string of outcomes in a particular experiment was as follows, with 'f' standing for 'failure' and 's' standing for 'success':
ffsffffsfsfssffsffffffsfsffsssfsffsfsffs
What should one make of such a string? Bamberger (1991) speaks of students' spontaneous graphic representations of sound sequences as modeling and thus revealing the students' idiosyncratic parsing of the string of auditory stimuli. Likewise, different parsings of probabilistic events reveal different interpretative underpinnings of the meaning of probability. It is important to stress that neither of the following interpretations is "correct" or "incorrect." They are each valid in their own way (see also "Prob Graphs Basic," part of the CCL "ProbLab" suite of models).
1.
"f f s f f f f s f s f s s f f s f
f f f f f s f s f f s s s f s f f s f s f f s." Taken as a string of 40
independent events, one can sum up the number of successes (15) and compute the
probability of a success as the ratio between successes and total outcomes,
i.e. ![]() . If the string were
long enough, we could argue for the successes-per-events ratio as being the
limiting value of this phenomenon. Note that such a perspective entirely
ignores the distribution of s's over the string and any variability that could
possibly be observed in this distribution.
. If the string were
long enough, we could argue for the successes-per-events ratio as being the
limiting value of this phenomenon. Note that such a perspective entirely
ignores the distribution of s's over the string and any variability that could
possibly be observed in this distribution.
2.
"ffsff ffsfs fssff sffff ffsfs
ffsss fsffs fsffs." Taking a statistical perspective, one may parse the string
into sub-strings of length 5 events each. Now we can compute the probability of
a success occurring in an individual sample: ![]() successes
per Sample of length 5 events, or .375 probability of success per single event.
Alternatively, first computing probabilities, one ends up with the same value:
successes
per Sample of length 5 events, or .375 probability of success per single event.
Alternatively, first computing probabilities, one ends up with the same value: ![]() .
.
3.
"ffs ffffs fs fs s ffs ffffffs fs
ffs s s fs ffs fs ffs." In a random string with a total of n attempts there is an unknown number of sub-strings,
each with a length of 1 through n
and ending with a success. This interpretative parsing of the events
corresponds, perhaps, to an activity in which a success is associated with relief
and momentary discontinuity of the search[3]). Here, the lengths of
the strings are 3, 5, 2, 2, 1, 3, 7, 2, 3, 1, 1, 2, 3, 2, 3. Thus, the average
length of an attempts-until-success sub-string is ![]() . Note that whereas in Interpretation #1
we computed
. Note that whereas in Interpretation #1
we computed ![]() (probability of
success per single outcome), here we computed
(probability of
success per single outcome), here we computed ![]() (average number of attempts until single success). This reciprocity is no
coincidence: In all interpretations, the '40' corresponded to the total number
of events and the '15' corresponds to the total number of successes. However,
each interpretation harbors a different model of the simulated probabilistic
phenomenon, leading to different forms of representation and subsequent statistical
inferences.
(average number of attempts until single success). This reciprocity is no
coincidence: In all interpretations, the '40' corresponded to the total number
of events and the '15' corresponds to the total number of successes. However,
each interpretation harbors a different model of the simulated probabilistic
phenomenon, leading to different forms of representation and subsequent statistical
inferences.
Interpretation #3
(samples per success) was DA's intuitive choice for parsing outcomes of the EP
modeled experiment, because as he watched the simulation run in real time, he
interpreted it as the creatures' successive failed attempts to meet that were
each capped by a single success. He graphed the distributed lengths of these
attempt-until-success substrings, and was surprised that this distribution did
not result in a bell-curved distribution, but rather in a ![]() �type curve (Figure 3, on left).
�type curve (Figure 3, on left).
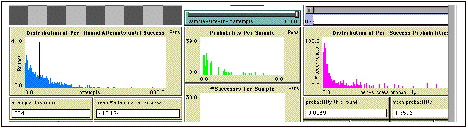
Figure 3: Fragment from Equidistant Probability. Central distribution is not bell curved because sample (1000 attempts) is too small relative to the frequency (1/432).
Guessing that perhaps instead
of attempts-per-success frequencies
he should rather have graphed the probabilities (the reciprocals of the per-success frequencies), he
created a different graph (Figure 3, on right) but this, too, resulted in a ![]() type graph and not in a bell-curve. Only
once he revisited his understanding of 'sample' did DA realize he should parse
strings of outcomes into sub-strings of equal length, tally the successes in
each, and form a distribution of these tallies (Interpretation #2,
above).
type graph and not in a bell-curve. Only
once he revisited his understanding of 'sample' did DA realize he should parse
strings of outcomes into sub-strings of equal length, tally the successes in
each, and form a distribution of these tallies (Interpretation #2,
above).
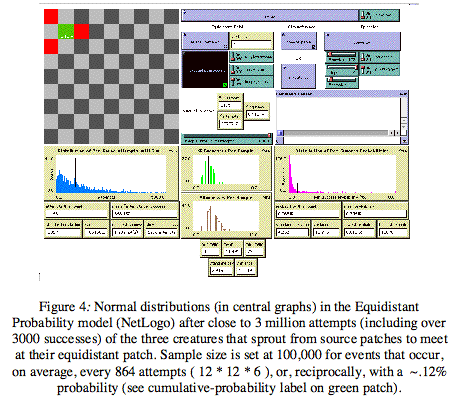
But even sampling, DA found, must be sensitive to the rarity of favored events: His distributions were coming out lopsided rather than bell-curved (Figure 3, center) because the samples he was taking were too small, e.g., 1000, for events that occur every 432 attempts, on average. Only once he tweaked the ratio between sample size and expected frequencies so as to both avoid "floor effects" (ratio is too low, so many samples have zero successes) and intractability (ratio is too high, so distribution evolves too slowly), did DA succeed in representing the experiment outcomes in the form of a bell curve (Figure 4, next page).
Note that DA's insight into the minimally sufficient sample-to-frequency ratio was informed by his understanding of the geometrical-determinism in this model. For example, he expected the frequency of events to converge on 1/432 because he had calculated the product of 6, 6, and 12, which were, respectively, the chance of each individual creature to step into the equidistant patch. These complementary perspectives on stochastics--geometric and probabilistic--converged in DA's process of making sense of the entire EP suite of models through their design.
Clearly, working in our microworld will be essentially different from working on it. A designer's productive learning-through-designing experience is hardly a criterion of a microworld's efficacy as a learning instrument. Nevertheless, we believe that essential aspects of DA's learning experience point to a general need in the Probability-and-Statistics curricula. Therefore, we have designed working in EP as an exploration that reconstructs the quest of the bell curve or any other quest. The improved model strives to be sufficiently complex so as to engage students in both theoretical and empirical probability yet not so complex that they cannot mathematize and relate these complementary interpretations (see Henry, 2001). Also, studentswill collaborate in our design and will be able to share and debate their emergent understandings (Abrahamson, Berland, Unterman, Shapiro, & Wilensky, 2003), once EP is implemented in several urban middle and high schools as part of CCL's Statistics-and-Probability model-based curriculum. Students' collaboration is expected to enhance the epistemological dialectic designed into EP, e.g., mathematical vs. empirical stochastics, because conversing students may take different sides as each works on, brings evidence from, and debates from a different sub-model perspective. Hopefully, such debate will help students reconcile, as a group and as individuals, complementary phenomenologies of probability.
The specific arena where such 'complementarity of levels of observation' (Wilensky & Stroup, 2000) acts out its dialectic is, perhaps, the ambiguous and rival interpretations we bring to bear while observing the model as it runs. Our anticipation of the model's convergence upon a particular statistical value, coming from the geometrical proof, espoused with our real-time perception of the emergent, fuzzy reality, captures the statistical moment as both chaotic and specific, thus affording the user an environment to develop a mature, integrative, and 'connected' conceptualization of stochastic behavior.
Abrahamson, D. & Wilensky, U. (2003a). Connecting to probability and statistics: From intuitions to graphs through self-authored computer-based experiments. Manuscript in preparation.
Abrahamson, D. & Wilensky, U. (2003b). Statistics as situated probability: The design and implementation of S.A.M.P.L.E.R. Manuscript under review.
Abrahamson, D., Berland, M.W., Shapiro, R. B., Unterman, J. W., & Wilensky, U. J. (2003). Collaborative interpretive argumentation as a phenomenological-mathematical negotiation: A case of statistical analysis of a computer simulation of complex probability. Manuscript under review.
Bamberger, J. (1991). The mind behind the musical ear. Cambridge, MA: Harvard University Press.
Biehler, R. (1995). Probabilistic thinking, statistical reasoning, and the search of causes: Do we need a probabilistic revolution after we have taught data analysis? Newsletter of the international study group for research on learning probability and statistics, 8(1). Accessed December 12, 2002. http://seamonkey.ed.asu.edu/~behrens/teach/intstdgrp.probstat.jan95.html
Gigerenzer, G. (1998). Ecological intelligence: An adaptation for frequencies. In D. D. Cummins & C. Allen (Eds.), The evolution of mind (pp. 9-29). Oxford: Oxford University Press.
Harel, I., & Papert, S. (1991). Software design as a learning environment. In I. Harel & S. Papert (Eds.), Constructionism (p. 41-84). Norwood, NJ: Ablex Publishing.
Henry, M. (Ed.). (2001). Autour de la modelisation en probabilities. Paris: Press Universitaire Franc-Comtoises.
Papert, S. (1980). Mindstorms. NY: Basic Books.
Papert, S. (1991). Situating constructionism. In I. Harel & S. Papert (Eds.), Constructionism (pp. 1 � 12). Norwood, NJ: Ablex Publishing Co.
Papert, S. (1996). An exploration in the space of mathematics educations. International Journal of Computers for Mathematical Learning, 1(1), 95-123.
Wilensky, U. (1993). Connected mathematics--Building concrete relationships with mathematical knowledge. Doctoral thesis, M.I.T.
Wilensky, U. (1996). Modeling rugby: Kick first, generalize later? International Journal of Computers for Mathematical Learning, 1(1), p. 124 - 131.
Wilensky, U. (1997). What is normal anyway?: Therapy for epistemological anxiety. Educational Studies in Mathematics 33(2), 171-202.
Wilensky, U. (1999). NetLogo. Evanston, IL. Center for Connected Learning and Computer-Based Modeling, Northwestern University. http://ccl.northwestern.edu/netlogo/
Wilensky, U. & Stroup, W. (2000). Embodied science learning: Students enacting complex dynamic phenomena with the HubNet architecture. Paper presented at the annual meeting of the American Educational Research Association. Seattle, WA.